Josh Cunningham wrote a piece called Imagining a Personal Data Pipeline. I started exploring his project, pdpl-cli, which helps you download your personal data and pipe it out to your desired output. I’ve been thinking extensively about this problem for a number of weeks now since I’ve exported my Google Contacts into Obsidian. However, with the lack of database support, I thought about self hosting it. Enter the Personal Data Pipeline.
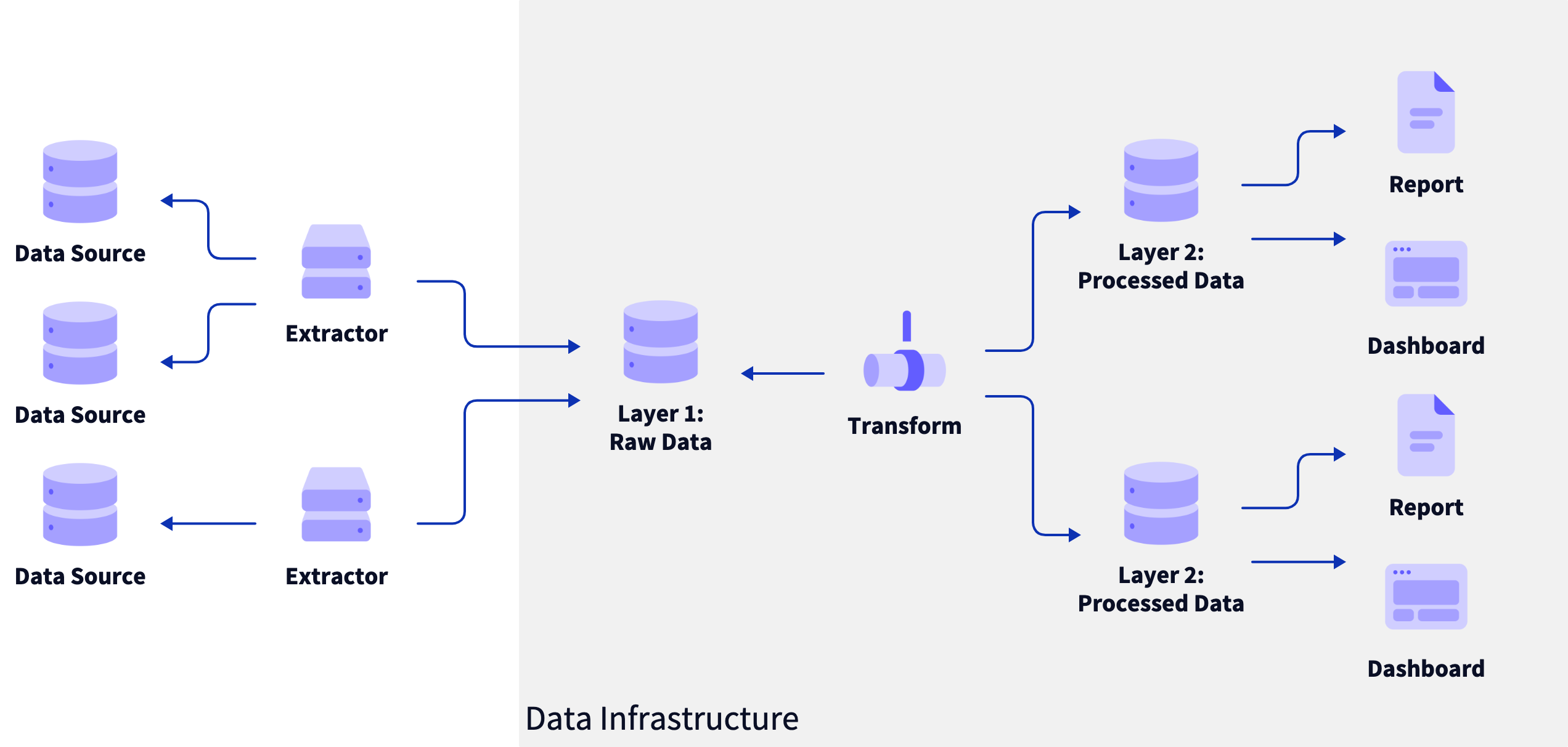
It’s essentially ETL jobs with integrations to third party services to “recipes” that you can write in yaml and customize to your desired outputs. I think this helps a lot more than determining data schemas for specific third party data integrations and having the raw data in a personal data lake. (Or really maybe a document store).
The idea is to have it local-first and maybe include a sync-thing or cloud syncing as an optional add-on. There’s an emphasis on privacy, although my bigger fear is vendor lock-in. I’ve become so reliant on Google, Apple, and other services that I don’t feel like I own my personal data anymore. Also, as a web developer, the hardest part is grabbing my own data from the sticky hands of these cloud services. Also, this emphasis on files over apps makes a lot more sense to me than the walled garden approach we’ve become accustomed to.